通知公告
通知公告
2022年 第26卷 第10期
2022, 26(10): 1117-1117.
doi: 10.16462/j.cnki.zhjbkz.2022.10.001
 摘要
摘要 HTML
HTML PDF
PDF
摘要:
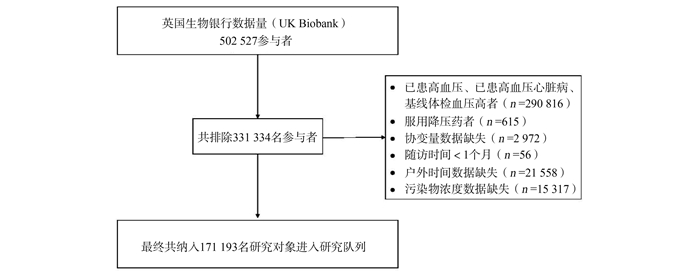
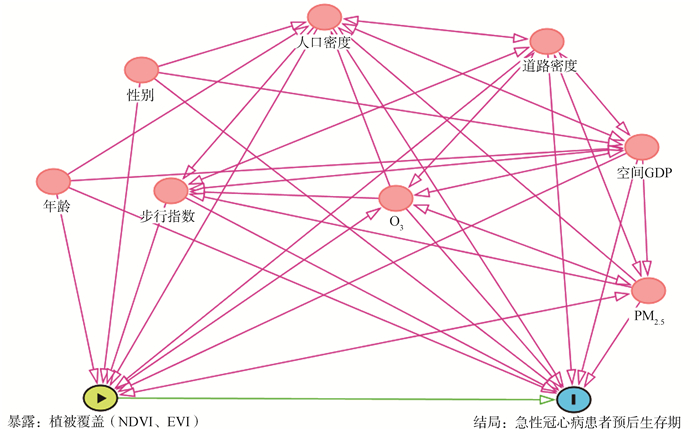
2022, 26(10): 1129-1136.
doi: 10.16462/j.cnki.zhjbkz.2022.10.004
摘要:
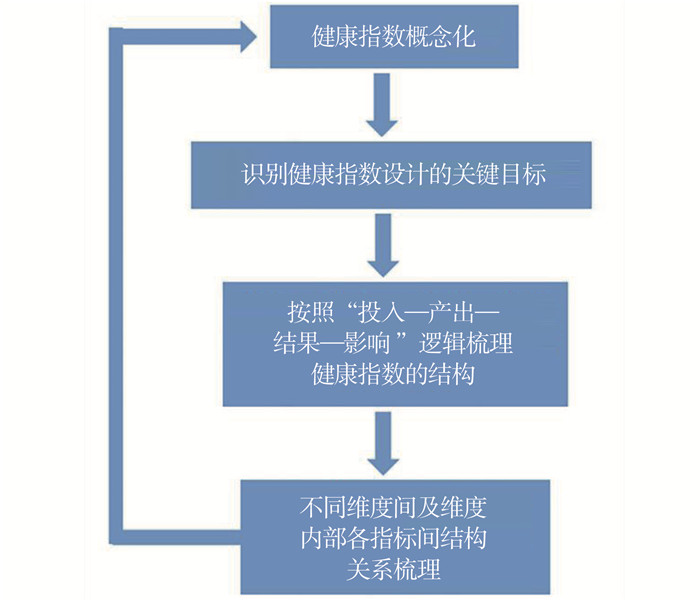
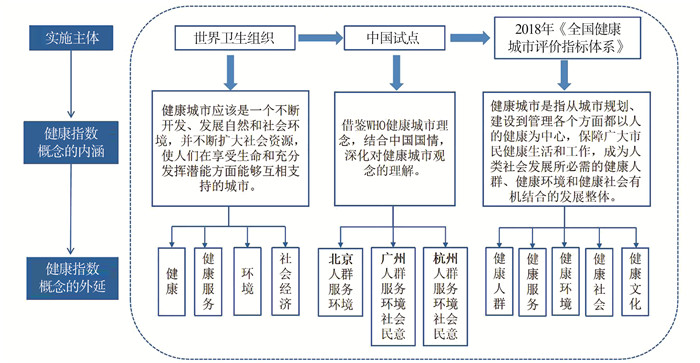
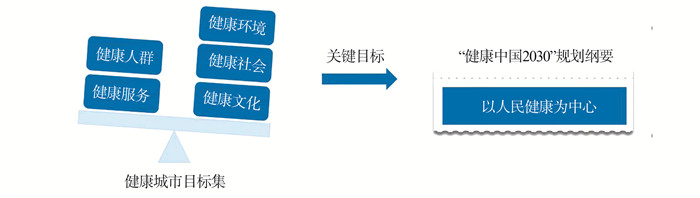
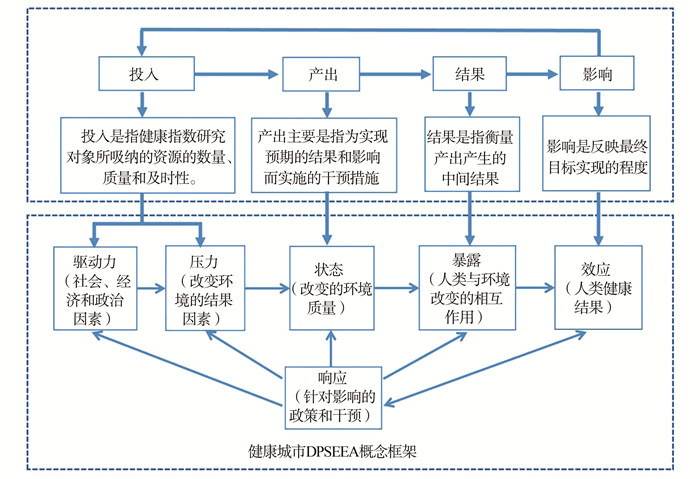
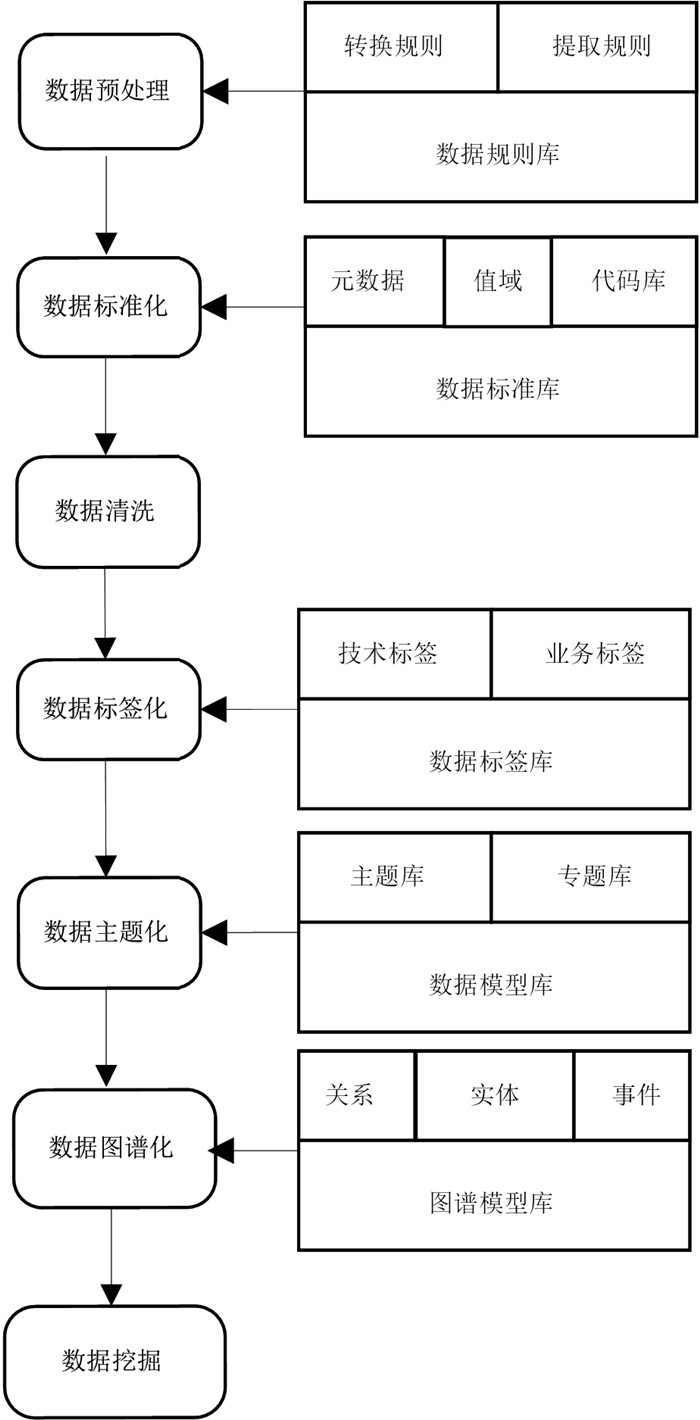
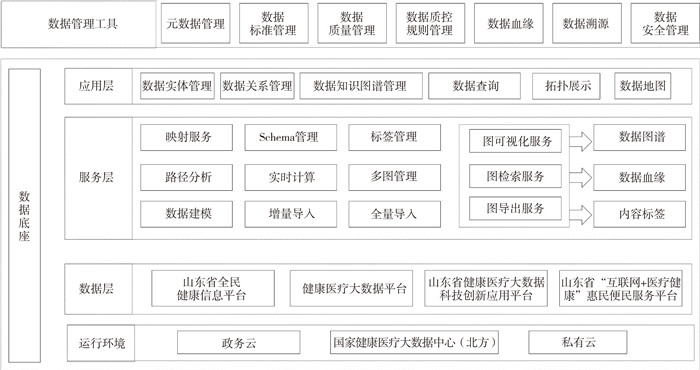
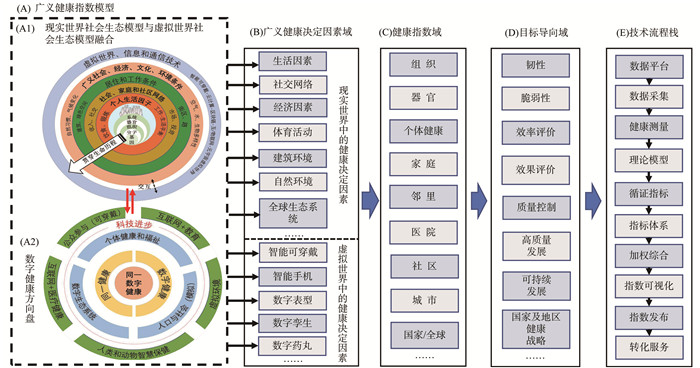
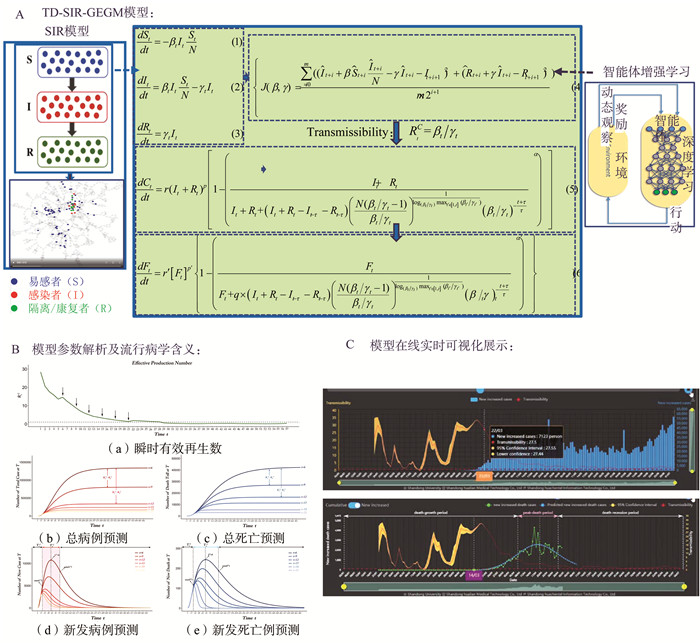
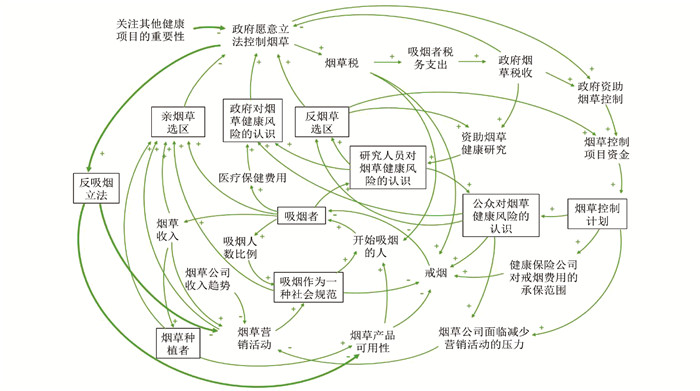
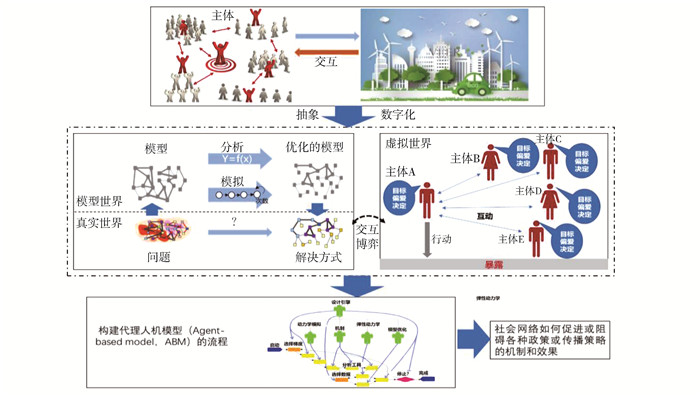
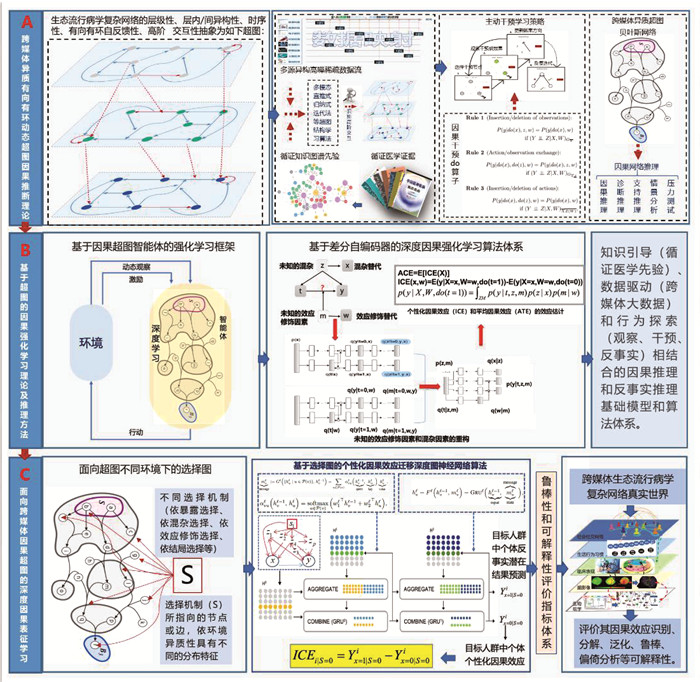
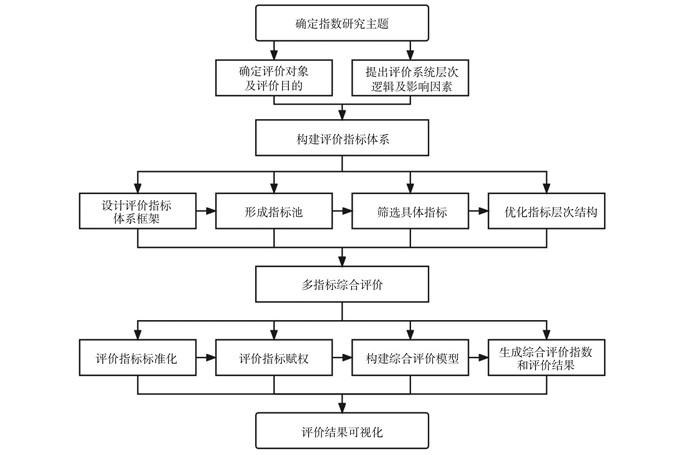
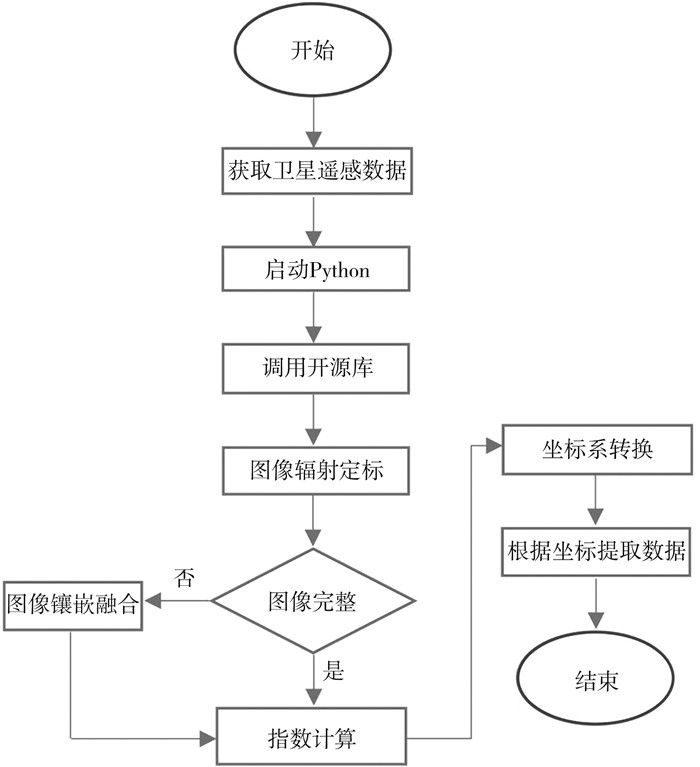
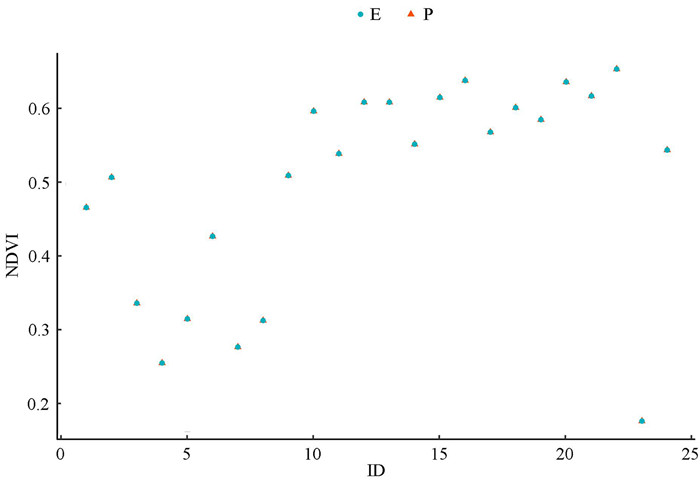
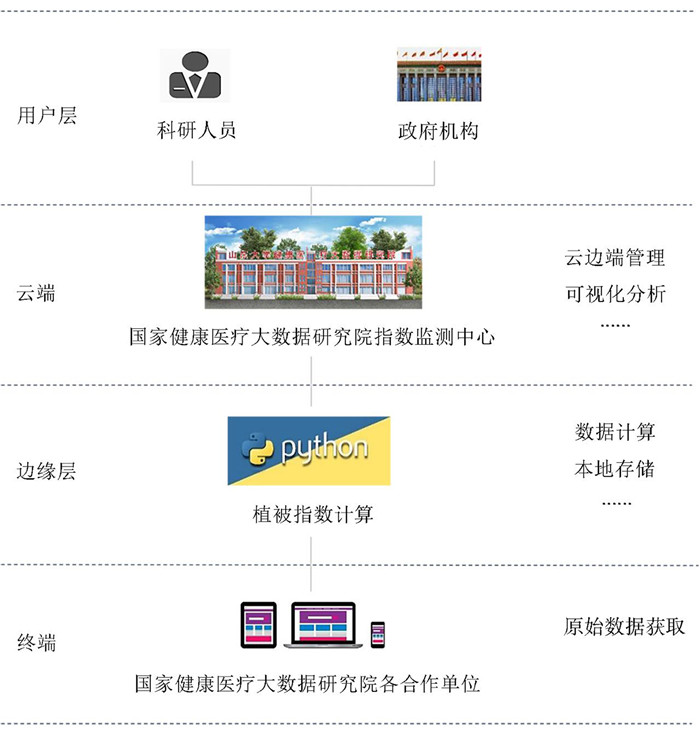
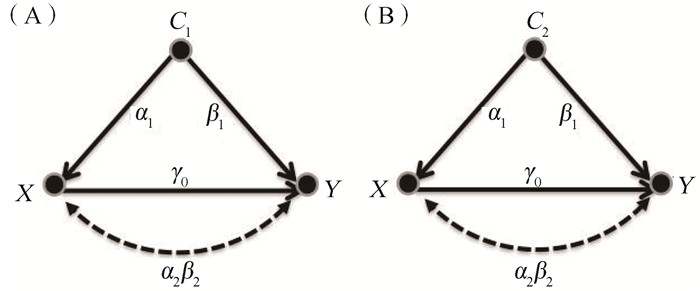
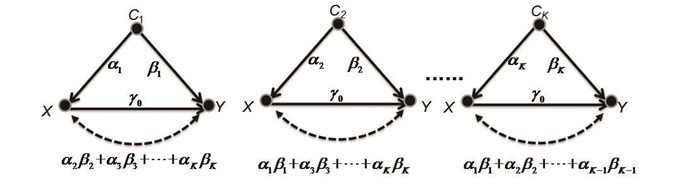
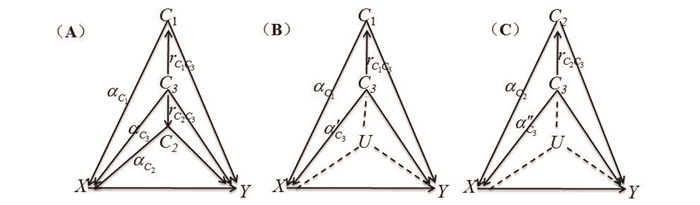
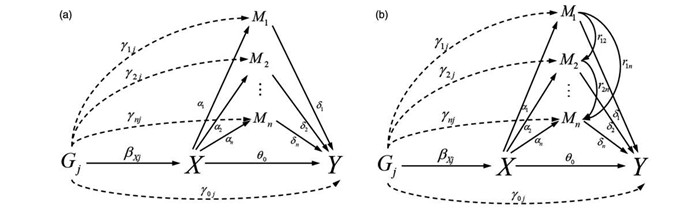
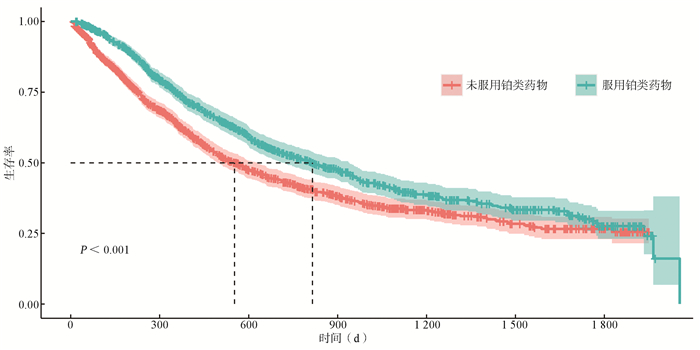
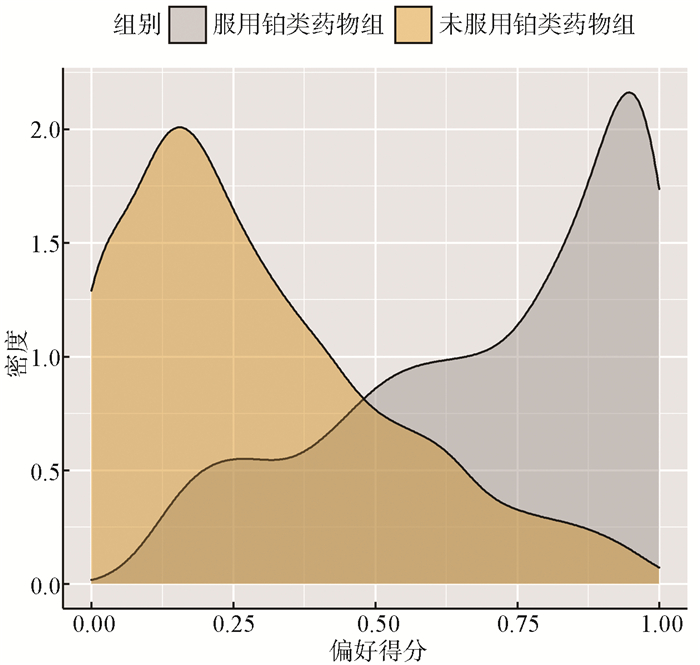
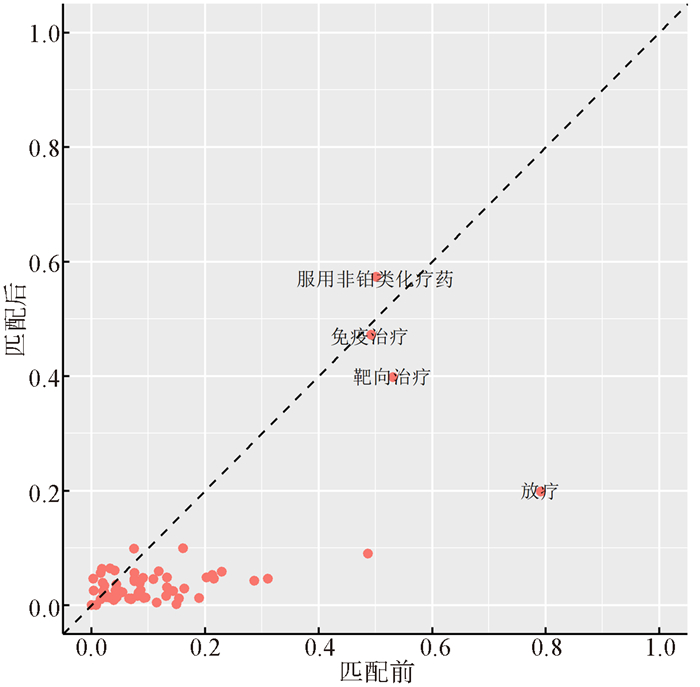
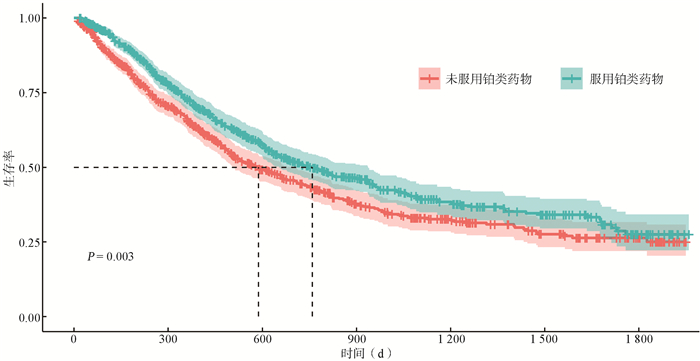
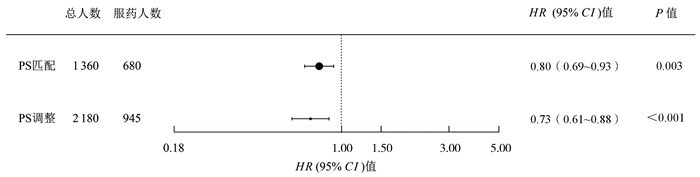

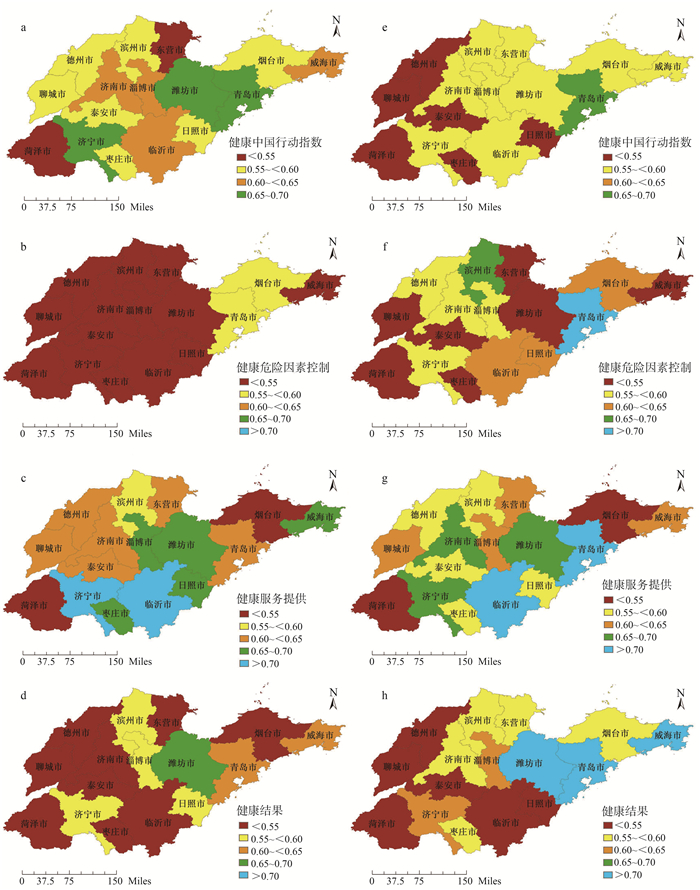
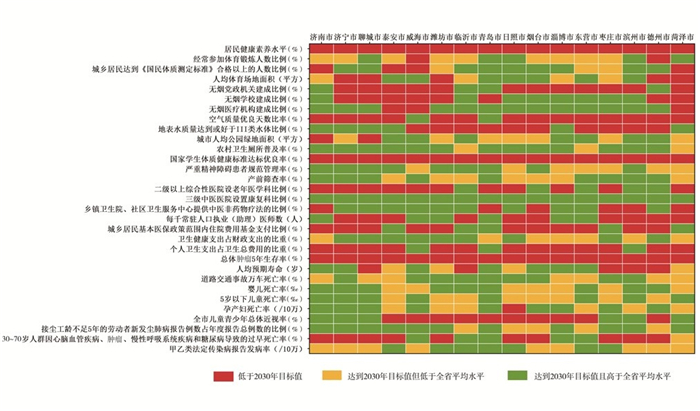
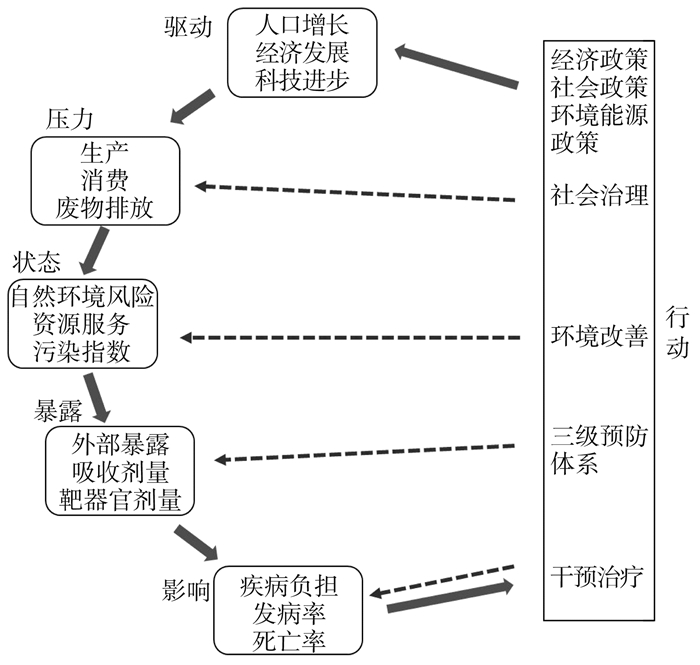
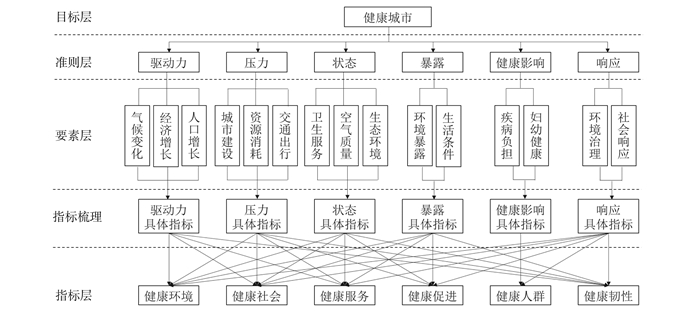
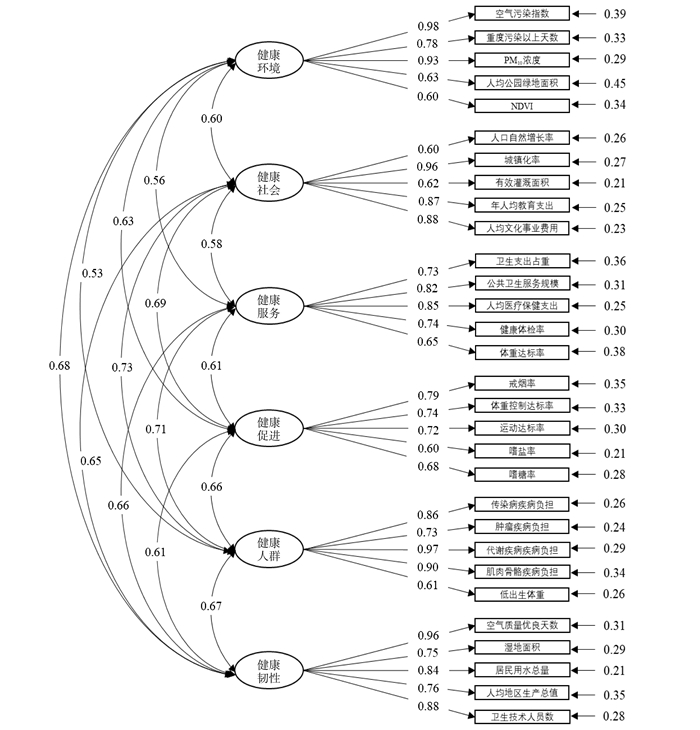
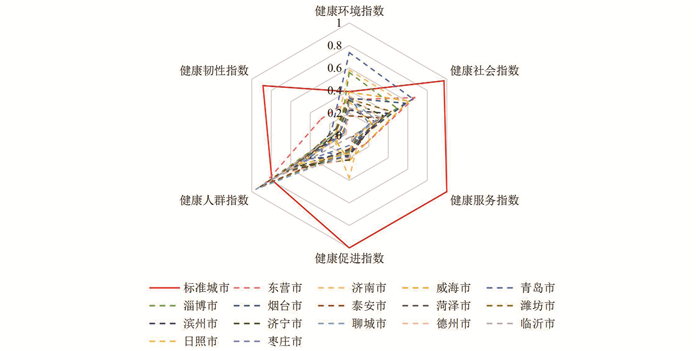
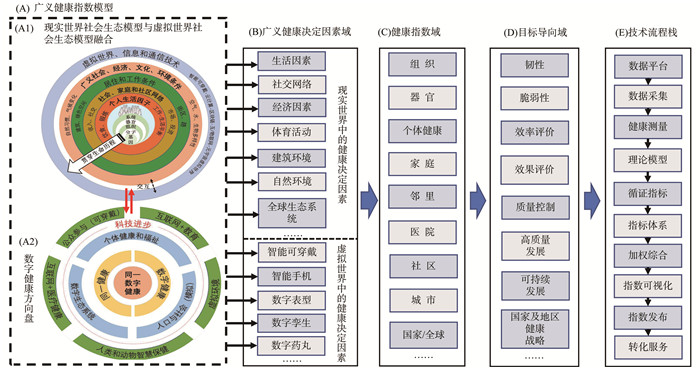
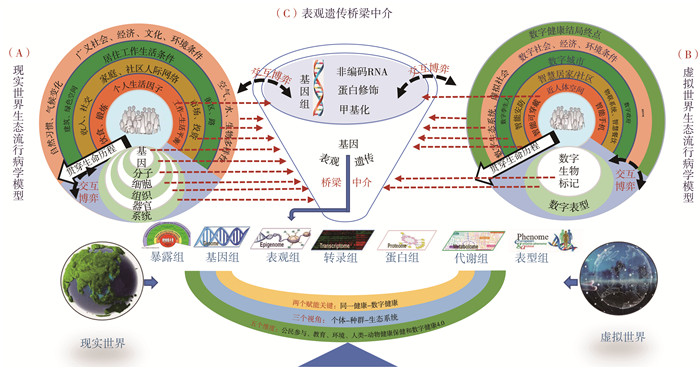
2022, 26(10): 1205-1209.
doi: 10.16462/j.cnki.zhjbkz.2022.10.016
摘要: