
 通知公告More+
通知公告More+
 微信二维码
微信二维码

扫一扫关注期刊公众号




优先发表栏目展示本刊经同行评议确定正式录用的文章,这些文章目前处在编校过程,尚未确定卷期及页码,但可以根据DOI进行引用。
显示方式:
2025, 29(6): 621-627.
doi: 10.16462/j.cnki.zhjbkz.2025.06.001
 摘要
摘要 HTML
HTML PDF
PDF
摘要:
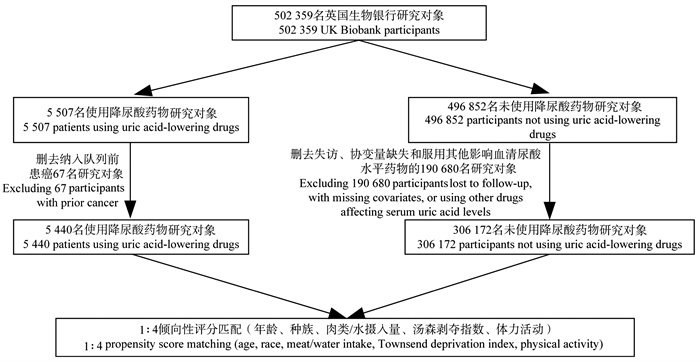
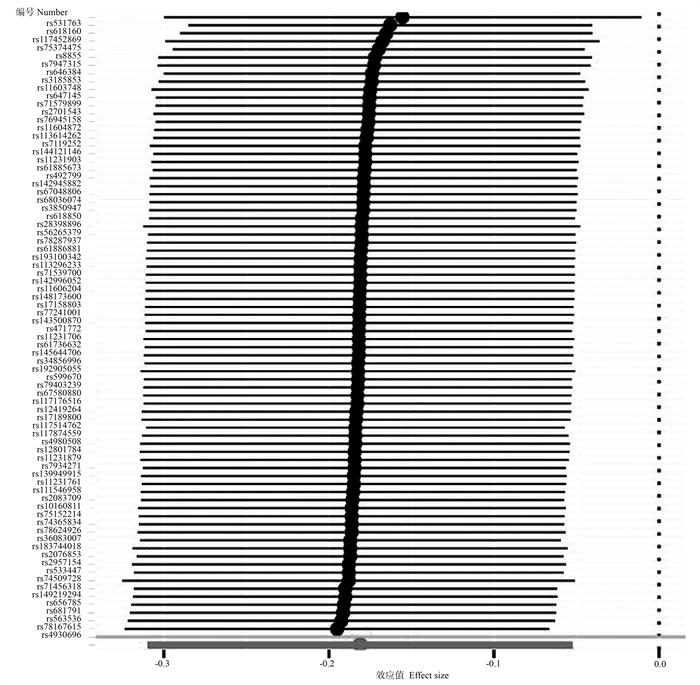
目的 评估降尿酸药物及其药物靶点与结直肠癌(colorectal cancer, CRC)发生的关联。 方法 基于英国生物银行2006―2010年的数据(申请号:62663)进行前瞻性队列研究,采用倾向性评分匹配和Cox比例风险回归模型探讨降尿酸药物的使用对CRC发生风险的影响。同时采用孟德尔随机化(Mendelian randomization, MR)方法,以降尿酸药物靶基因的表达数量性状位点作为工具变量,分析3类降尿酸药物与CRC发生的关联性。 结果 研究共纳入5 440名降尿酸药物使用者,年龄中位数为52.0岁,92.1%为男性,中位随访12.75年,共发生117例CRC。Cox比例风险回归模型显示,降尿酸药物使用者的CRC发生风险比未使用降尿酸药物者降低了20.2%(HR=0.798, 95% CI: 0.652~0.976, P=0.029)。MR分析表明,以溶质载体家族22成员12(solute carrier family 22 member 12, SLC22A12)作为治疗靶点可以降低CRC的发生风险(OR=0.834, 95% CI: 0.734~0.949, P=0.006)。 结论 降尿酸药物和SLC22A12靶向的促尿酸排泄剂与CRC发生相关,为解释降尿酸药物与CRC的关联提供了可能的线索。
2025, 29(6): 628-635.
doi: 10.16462/j.cnki.zhjbkz.2025.06.002
摘要:
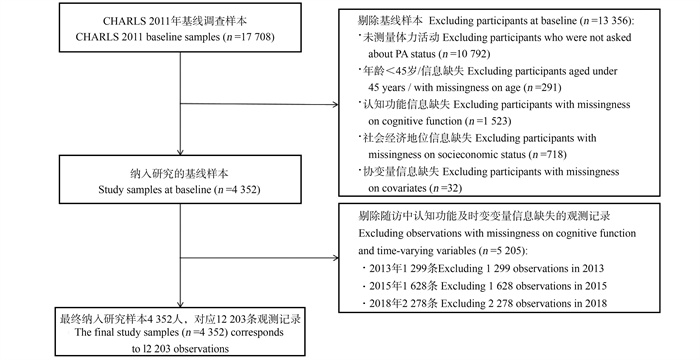
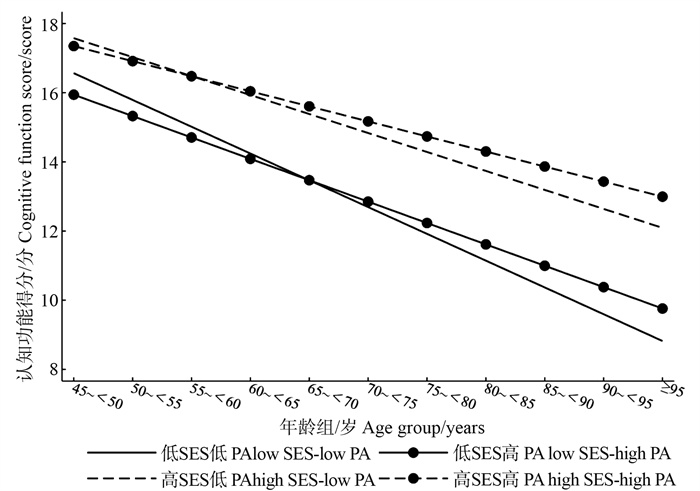
目的 探究中国中老年人社会经济地位(socioeconomic status, SES)和体力活动(physical activity, PA)对认知功能衰退的联合影响。 方法 选取中国健康与养老追踪调查中2011―2018年的4轮数据,在基线纳入4 352名≥45岁的中老年人作为研究样本。根据SES和PA,将其分为4组:低SES低PA、低SES高PA、高SES低PA和高SES高PA。采用线性混合效应模型进行分析。 结果 研究样本总体的基线认知功能得分平均为(15.02±4.67)分,不同SES-PA分组间的认知功能得分差异有统计学意义。回归模型结果显示,在控制混杂因素后,与低SES组相比,高SES组的认知功能水平更高(β高SES低PA=0.96, P=0.008; β高SES高PA=0.73, P=0.022);此外,SES及PA的提升均能减缓认知功能的衰退速度(β年龄×低SES高PA=0.03, P=0.047; β年龄×高SES低PA=0.05, P=0.010; β年龄×高SES高PA=0.07, P<0.001)。综合来看,高SES高PA组认知功能水平最高且认知功能衰退速度最慢。 结论 随着年龄的增长,认知功能在人群中主要表现为SES的差异,但PA水平在其中起到一定的调节作用。鉴于PA干预措施的成本效益更高,未来需进一步关注体质锻炼在提升中老年人认知健康方面的作用。
2025, 29(6): 636-640.
doi: 10.16462/j.cnki.zhjbkz.2025.06.003
摘要:
目的 分析中国帕金森病(Parkinson′s disease, PD)流行状况及发病趋势,为制定PD防控政策提供科学依据。 方法 采用年龄-时期-队列(age-period-cohort, APC)模型,对1990―2021年中国PD患病率及发病率进行分析,评估不同年龄、时间段及出生队列对PD流行趋势的影响。通过差分自回归移动平均(autoregressive integrated moving average, ARIMA)模型,对2024―2030年PD发病率进行预测。 结果 1990―2021年,中国PD年龄标准化发病率由12.8/10万上升至24.3/10万(P<0.001),死亡率则从6.80/10万下降至5.03/10万(P<0.001)。PD在≥30岁人群中发病率迅速升高,70~<75岁年龄组发病人数最多(81 945人)。基于ARIMA模型预测,到2030年,全国PD发病率预计将上升至26.52/10万(95% CI:24.73/10万~28.31/10万),其中男性为35.20/10万(95% CI:33.20/10万~37.21/10万),女性为20.96/10万(95% CI:20.27/10万~21.65/10万)。 结论 中国PD疾病负担加剧,发病人群以老年人为主,且存在性别差异。预测未来PD发病率仍呈上升趋势,需进一步加强PD的早期诊断、预防和管理,以减轻公共卫生负担。
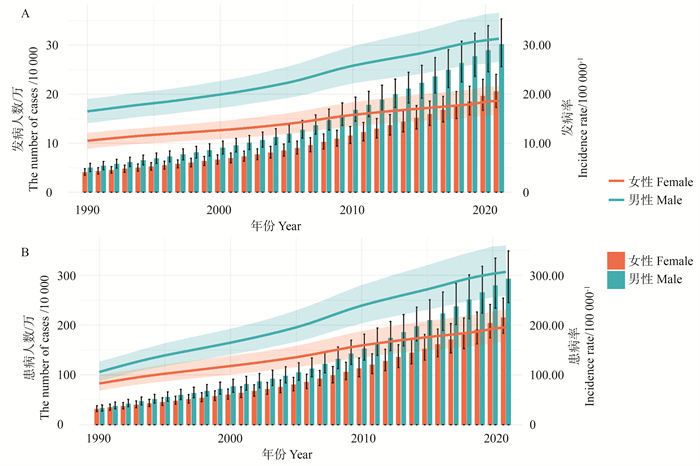
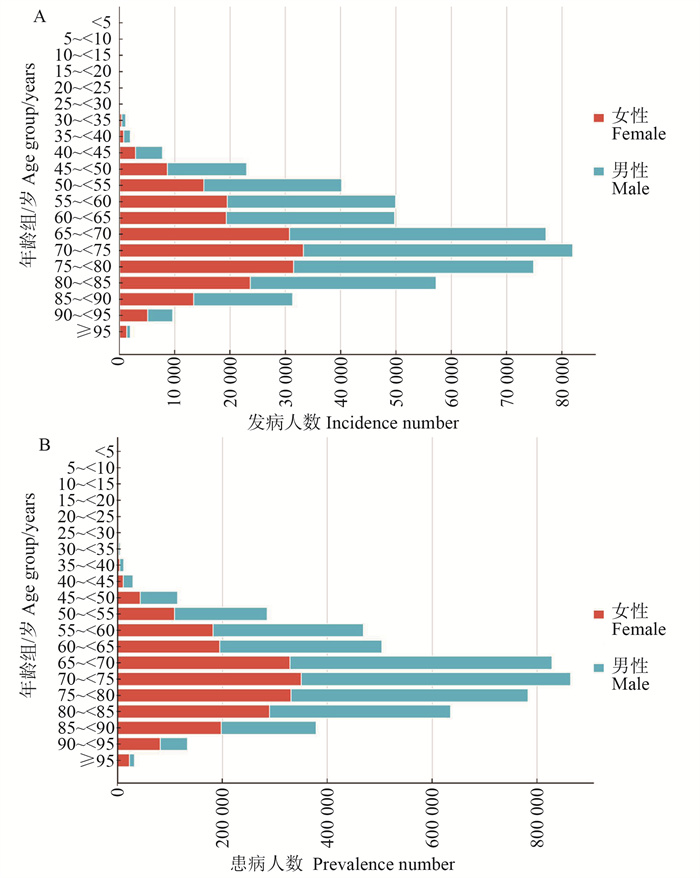
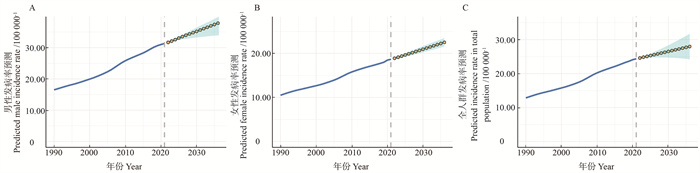
2025, 29(6): 641-653.
doi: 10.16462/j.cnki.zhjbkz.2025.06.004
摘要:
目的 探讨沉默信息调节因子1(silent information regulator 1, SIRT1)基因多态性及其与孕前BMI、孕早期增重的交互作用对子痫前期(pre-eclampsia, PE)发生风险的影响。 方法 2020年10月―2023年10月在中南大学湘雅三医院和湖南省妇幼保健院产科开展病例对照研究,将诊断为PE的孕妇作为病例组,同期在这2所医院产检且血压正常的孕妇作为对照组。对研究对象进行问卷调查,并采集血液样本进行基因分型检测。采用logistic回归分析孕前BMI、孕早期增重和SIRT1基因多态性与PE发生的关联,并采用叉生分析和多因素logistic回归探讨SIRT1基因多态性与孕前BMI、孕早期增重的交互作用对PE发生的影响。 结果 共纳入研究对象602例(病例组202例,对照组400例)。孕前BMI过高孕妇发生PE的风险是孕前BMI正常孕妇的5.21倍(OR=5.21, 95% CI: 3.15~8.63),孕早期增重过多的孕妇发生PE的风险是孕早期增重适宜孕妇的3.38倍(OR=3.38, 95% CI: 2.20~5.18)。SIRT1基因rs2236319位点(加性模型:aOR=1.40, 95% CI: 1.01~1.95)、rs3740051位点(显性模型:aOR=1.59, 95% CI: 1.06~2.37;加性模型:aOR=1.51, 95% CI: 1.08~2.11)、rs10823108位点(显性模型:aOR=1.50, 95% CI: 1.01~2.23;加性模型:aOR=1.43, 95% CI: 1.02~1.99)与PE的发生风险增加相关。SIRT1基因rs11599176位点(共显性模型:aOR=0.65, 95% CI: 0.43~0.98;显性模型:aOR=0.62, 95% CI: 0.42~0.93;加性模型:aOR=0.66, 95% CI: 0.47~0.92)与PE的发生风险降低相关。未观察到SIRT1基因多态性与孕前BMI、孕早期增重对PE的影响存在交互作用。 结论 孕前BMI过高以及孕早期增重过多可能导致PE的发生风险增加。SIRT1基因rs11599176、rs2236319、rs3740051和rs10823108位点多态性与PE的发病可能有关。此外,SIRT1基因多态性与孕前BMI、孕早期增重对PE发生的影响均不存在交互作用。
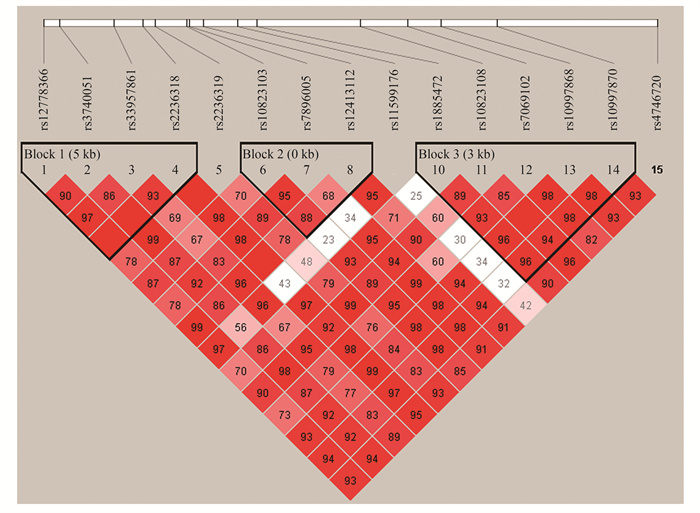
2025, 29(6): 654-661.
doi: 10.16462/j.cnki.zhjbkz.2025.06.005
摘要:
目的 探讨山西省某煤矿集团男性职工职业暴露与子代常见疾病和发育行为障碍的关系,为煤矿职工子代疾病的早期防治提供参考依据。 方法 采用横断面调查的方法,于2023年对西山煤电(集团)有限责任公司某煤矿的在岗男性职工进行问卷调查,收集其社会人口学、生活方式和职业史等信息,并由研究对象报告子代的生长发育和常见疾病患病情况。运用logistic回归分析职业暴露与子代常见疾病和发育行为障碍的关系。 结果 共纳入7 085名男性煤矿职工,其子代总数为9 963名。调整混杂因素后,男性职工暴露于噪声(OR=1.559, 95% CI: 1.216~1.998)、粉尘(OR=1.425, 95% CI: 1.105~1.838)、有毒有害气体(OR=1.381, 95% CI: 1.096~1.740)、工频电场(OR=1.496, 95% CI: 1.050~2.131)和高湿环境(OR=1.441, 95% CI: 1.095~1.896)与子代常见疾病存在关联,尚未发现职业暴露与子代发育行为障碍之间的关联。 结论 噪声、粉尘、有毒有害气体、工频电场和高湿环境是子代常见疾病的危险因素。
2025, 29(6): 662-668.
doi: 10.16462/j.cnki.zhjbkz.2025.06.006
摘要:
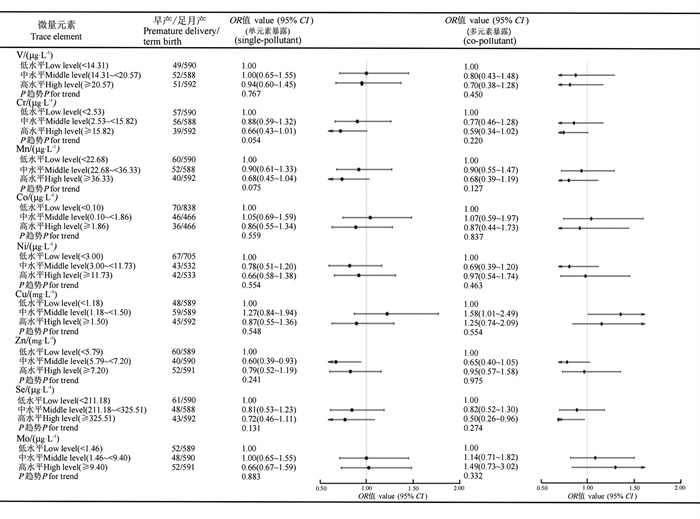
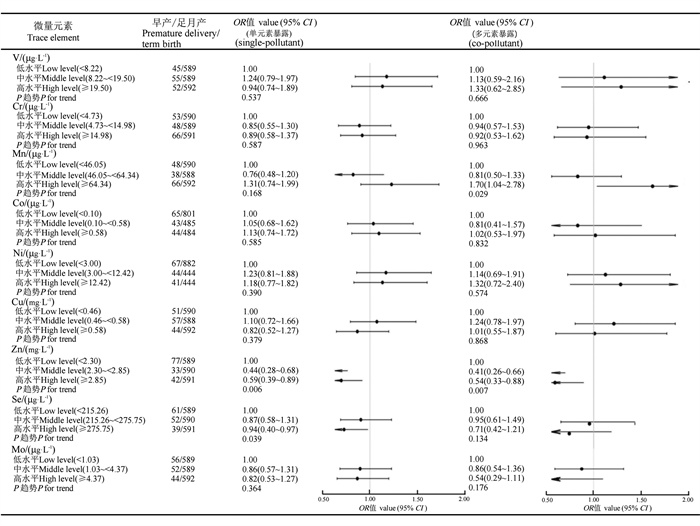
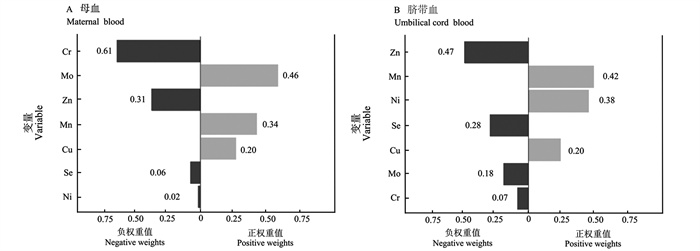
目的 了解孕妇微量元素内暴露水平,探讨多种微量元素联合暴露与早产的关系。 方法 选取2012年3月―2016年2月于山西医科大学第一医院产科住院分娩的1 922对母婴作为研究对象,采用感耦合等离子体质谱法测定母血及脐带血中钒(Vanadium, V)、铬(Chromium, Cr)、锰(Manganese, Mn)、钴(Cobalt, Co)、镍(Nickel, Ni)、铜(Copper, Cu)、锌(Zinc, Zn)、硒(Selenium, Se)、钼(Molybdenum, Mo)的浓度,利用分位数g-计算(quartile g-computation, QGCOMP)分析多种微量元素联合暴露与早产的关系。 结果 与Cu低水平相比,母血Cu中水平是早产的危险因素(OR=1.58, 95% CI:1.01~2.49);与Se低水平相比,母血Se高水平是早产的保护因素(OR=0.50, 95% CI:0.26~0.96);与Mn低水平相比,脐带血Mn高水平是早产的危险因素(OR=1.70, 95% CI:1.04~2.78);与Zn低水平相比,脐带血Zn中水平(OR=0.41, 95% CI:0.26~0.66)和高水平(OR=0.54, 95% CI:0.33~0.88)均是早产的保护因素。QGCOMP分析 结果 显示,母血、脐带血中微量元素联合暴露对早产影响的总效应值分别为-0.53(95% CI:-0.86~-0.19)、-0.47(95% CI:-0.84~-0.09)。母血中微量元素联合暴露对降低孕妇早产发生贡献程度最大的是Cr,脐带血微量元素联合暴露中Zn的负向权重最大。 结论 微量元素联合暴露与早产的发生有关,Zn、Se和Cr高水平能够降低早产的发生风险。
2025, 29(6): 669-674.
doi: 10.16462/j.cnki.zhjbkz.2025.06.007
摘要:
目的 了解心血管病高危人群脂质蓄积指数(lipid accumulation product index, LAP)与颈动脉粥样硬化发病风险的相关性,为心血管病高危人群的干预提供科学依据。 方法 基于2015年9月―2016年6月国家心血管病高危人群早期筛查与综合干预项目,通过问卷调查、体格测量、实验室检测和颈动脉超声检查等方法,采用χ2/F检验对不同性别、不同年龄心血管病高危人群的一般情况进行分析,并将可能的混杂因素进行调整,采用多因素logistic回归分析模型探讨LAP与颈动脉粥样硬化的关系。 结果 相比于男性、>60岁人群,女性、≤60岁人群的LAP更高,差异均有统计学意义(均P < 0.001)。回归分析结果显示,LAP每增加1个标准差,颈动脉斑块的发生风险增加6%(OR=1.06, 95% CI: 1.01~1.12, P=0.026)。交互作用结果显示,相比于女性、不饮酒者,男性、饮酒人群中LAP高者发生颈动脉斑块的风险更高(交互作用均P < 0.05)。 结论 心血管病高危人群中,LAP与颈动脉斑块呈正相关,且在男性、饮酒者中正相关性更强。
2025, 29(6): 675-681.
doi: 10.16462/j.cnki.zhjbkz.2025.06.008
摘要:
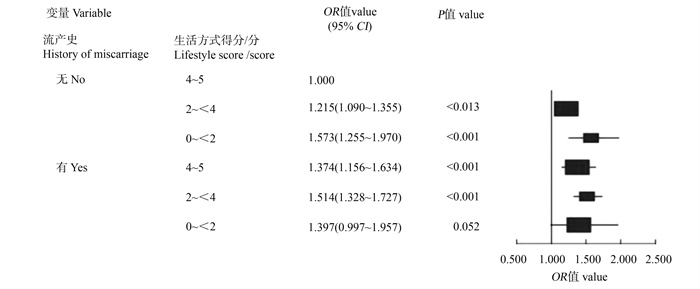
目的 探究≥65岁农村地区女性高血压患者生育史、生活方式与患心血管病(cardiovascular disease, CVD)风险的关系,并进一步探讨二者的联合作用。 方法 采用整群抽样方法,于2023年7―8月对河南省某县老年女性高血压患者进行问卷调查和体格检查。生育史包括怀孕次数、活产婴儿数和流产史,生活方式包括睡眠、饮食、体力活动、被动吸烟和BMI。采用logistic回归分析生育史、生活方式以及二者的联合作用对农村地区老年女性患CVD风险的影响。 结果 纳入分析的研究对象共9 837人,CVD患者3 980人。Logistic回归分析结果显示,怀孕≥5次、有流产史者患CVD的风险分别增加19.8%(OR=1.198, 95% CI: 1.057~1.359)、26.1%(OR=1.261, 95% CI: 1.151~1.381),生活方式得分为4~5分者患CVD的风险下降28.4%(OR=0.716, 95% CI: 0.592~0.866)。怀孕次数、流产史与生活方式对患CVD的风险存在联合作用,怀孕≥5次时,生活方式得分与患CVD的风险呈负相关。无论是否流产,生活方式得分与患CVD的风险均呈负相关。 结论 农村地区老年女性高血压患者中,怀孕次数较多、有流产史且健康生活方式较少是CVD防控的重点人群,应加强并提升生活方式教育,促进第一级预防的实施。

2025, 29(6): 682-687.
doi: 10.16462/j.cnki.zhjbkz.2025.06.009
摘要:
目的 构建及验证用于预测非酒精性脂肪性肝病(non-alcoholic fatty liver disease, NAFLD)的机器学习(machine learning, ML)模型,并筛选出最优模型,通过SHapley加性解释(SHapley Additive exPlanations, SHAP)框架解释该模型。 方法 选取美国国家健康与营养调查数据库中2017年1月―2020年3月的数据,按7∶3随机分为训练集和测试集。最小绝对收缩和选择算子回归用于特征选择,采用6种算法构建预测模型。使用受试者工作特征曲线下面积(area under curve, AUC)对模型进行评价,并通过校准曲线、决策曲线分析、变量重要性图、SHAP图进行解释。 结果 6 918名研究对象中,3 974人(57.44%)被诊断为NAFLD。极限梯度提升(eXtreme gradient boosting, XGBoost)模型综合表现优于其他模型,在测试集上的AUC为0.851,准确率为0.757,灵敏度为0.760,特异度为0.754。主要预测因子包括身体圆度指数、腰围、三酰甘油-葡萄糖指数、谷丙转氨酶、糖化血红蛋白和高密度脂蛋白胆固醇。在模型应用方面,开发了一个用户界面供医务人员使用。 结论 研究构建并验证了6种用于预测NAFLD的ML模型,其中XGBoost模型更具优势,可为临床早期筛查NAFLD高危患者提供可靠的参考依据。
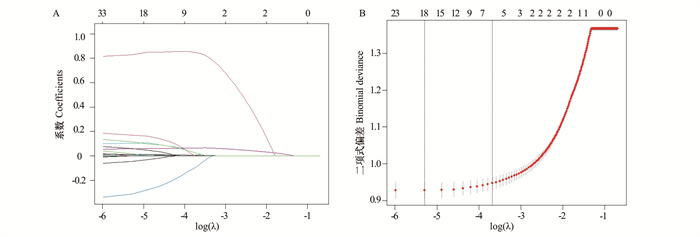
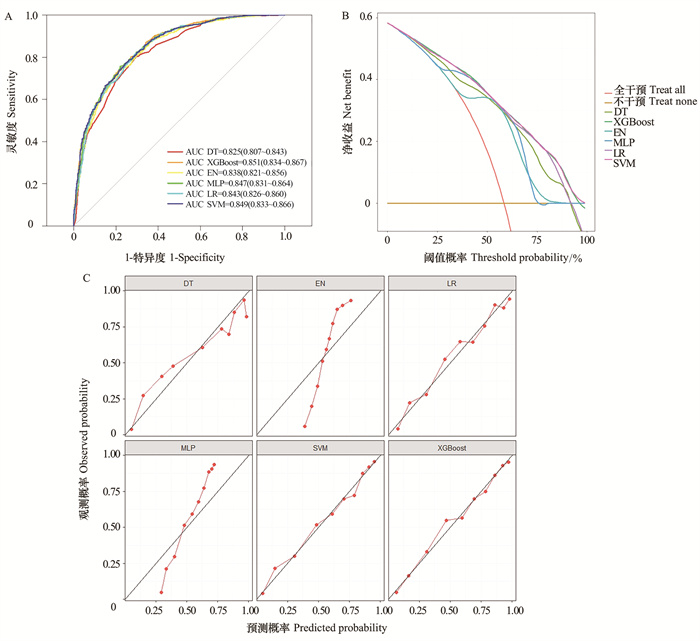
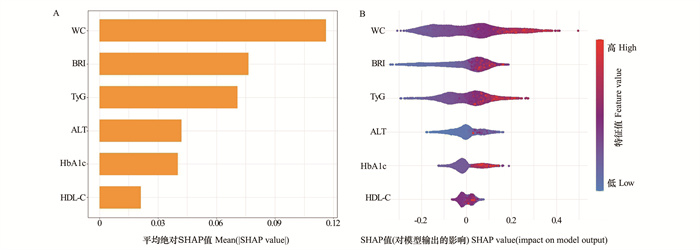
2025, 29(6): 688-696.
doi: 10.16462/j.cnki.zhjbkz.2025.06.010
摘要:
目的 探讨煤矿工人三酰甘油葡萄糖-体质量指数(triglyceride glucose-body mass index, TyG-BMI)变化轨迹与新发非酒精性脂肪性肝病(non-alcoholic fatty liver disease, NAFLD)的关联。 方法 作为回顾性队列研究,连续选取2015年1月2日―2023年12月29日在山西省某煤矿集团先后参与≥4次健康体检的15 186名职业人群作为研究对象,收集其人口学信息、人体测量数据和生化指标等信息。采用群组化轨迹模型构建4个不同的TyG-BMI轨迹组,采用Log-rank比较各轨迹组间NAFLD累积风险的差异,采用Cox比例风险回归模型分析TyG-BMI各轨迹与NAFLD发病风险的相关性。 结果 在(5.56±1.96)年随访期间,总人群NAFLD的累积发病率为32.44%。TyG-BMI低速增长组、中速增长组、高速增长组和急速增长组人群NAFLD的累积发病率分别为16.19%、24.25%、45.09%和68.78%,差异均有统计学意义(均P<0.001)。与低速增长组相比,中速增长组、高速增长组和急速增长组的NAFLD风险分别增加了0.435(HR=1.435, 95% CI:1.299~1.584)、1.895倍(HR=2.895, 95% CI:2.621~3.197)和4.451倍(HR=5.451, 95% CI:4.849~6.127)(均P<0.001)。亚组分析中,在年龄<40岁、文员和无高血压的TyG-BMI水平急速增长人群中观察到更高的NAFLD风险。 结论 TyG-BMI轨迹水平升高与NAFLD的发病风险呈正相关,TyG-BMI水平急速上升可能是NAFLD发生的危险因素。长期监测TyG-BMI水平,并对急速增长的人群进行及时干预,对早期预防NAFLD具有积极作用。
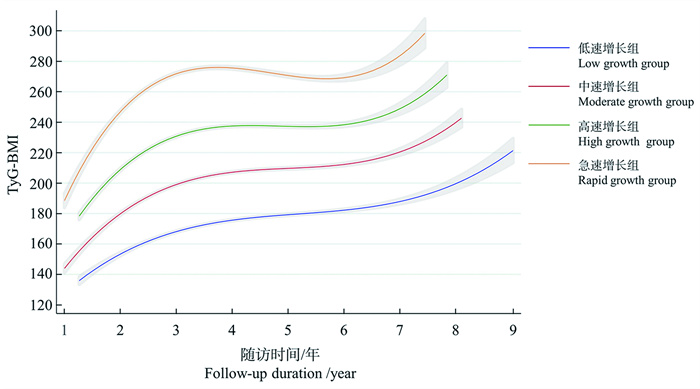
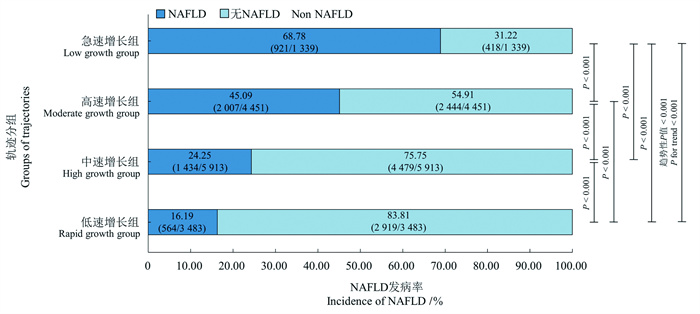
2025, 29(6): 697-705.
doi: 10.16462/j.cnki.zhjbkz.2025.06.011
摘要:
目的 通过开展全国多中心横断面研究,探讨不同代谢肥胖表型与人群患胆结石风险的关联性。 方法 连续纳入2015―2020年在重庆市和北京市4所三级甲等医院健康体检的研究对象,采用多因素logistic回归分析,比较代谢健康非肥胖(metabolically healthy non-obese, MHNO)、代谢健康型肥胖(metabolically healthy obesity, MHO)、代谢异常型非肥胖(metabolically unhealthy non-obese, MUNO)、代谢异常型肥胖(metabolically unhealthy obesity, MUO)与人群患胆结石风险的关联性,再采用随机效应模型对4个中心的结果进行Meta分析合并。 结果 共招募522 958名研究对象,胆结石总患病率为7.5%。MUO、MUNO、MHO和MHNO组胆结石患病率分别为9.4%、8.3%、6.5%和4.2%,组间差异均有统计学意义(均P < 0.05)。与MHNO组相比,MHO组患胆结石的风险增加了35.8%(合并OR=1.358, 95% CI: 1.213~1.520, P < 0.001);MUNO组患胆结石的风险增加了34.3%(合并OR=1.343, 95% CI: 1.211~1.489, P < 0.001);MUO组患胆结石的风险增加了48.9%(合并OR=1.489, 95% CI: 1.221~1.817, P < 0.001)。亚组分析显示,在不同性别和年龄组中,代谢肥胖表型与人群患胆结石风险的关联性差异均无统计学意义(均P>0.05)。 结论 无论是否伴随代谢异常,肥胖群体均会增加患胆结石的风险。未来应对肥胖群体,尤其是伴有代谢异常者,进行早期筛查与干预,以减少胆结石的疾病负担。
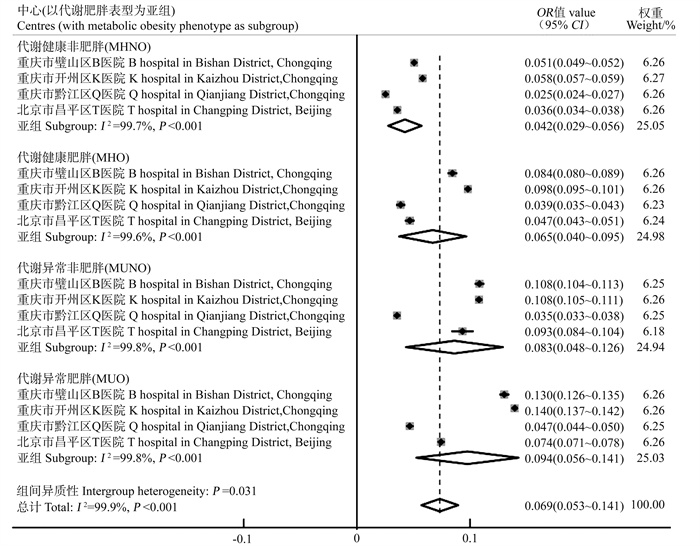
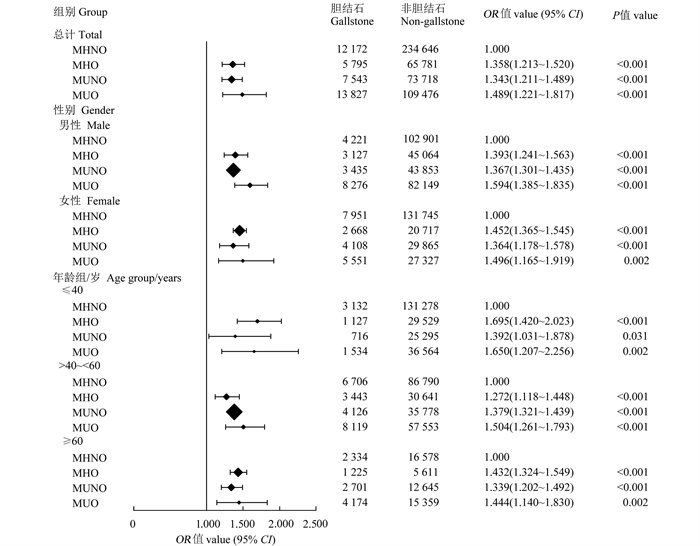
2025, 29(6): 706-712.
doi: 10.16462/j.cnki.zhjbkz.2025.06.012
摘要:
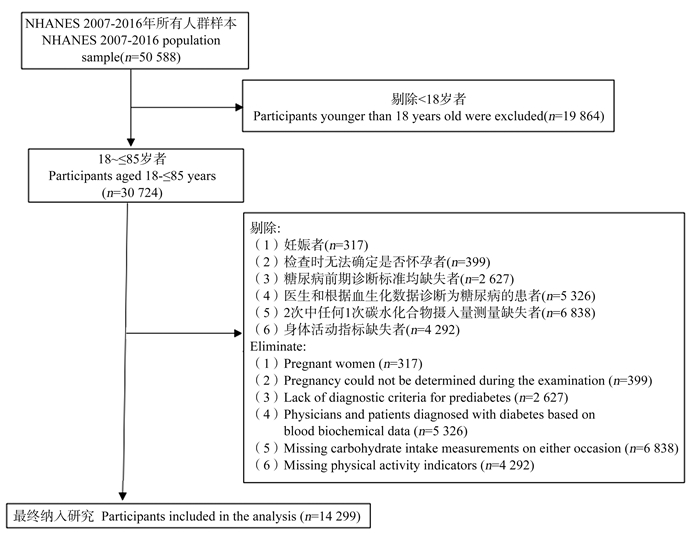
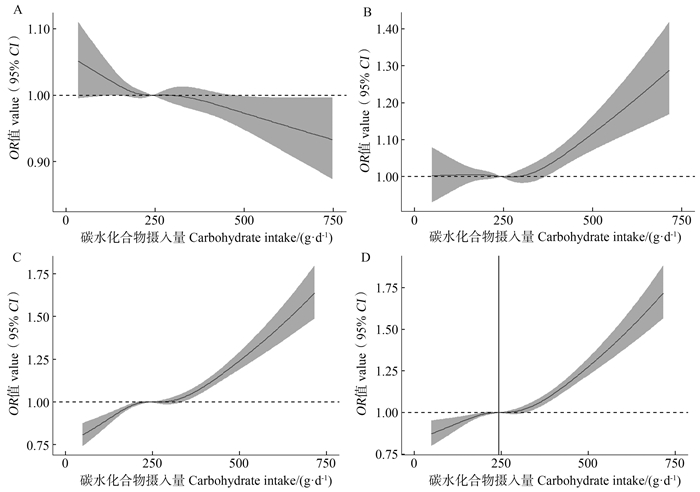
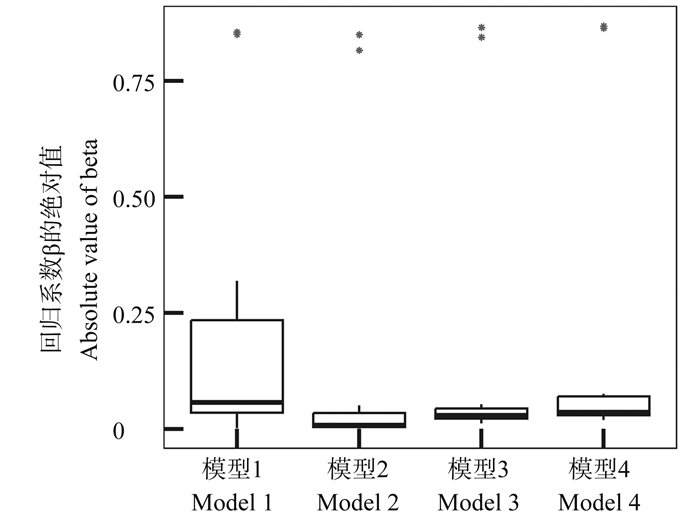
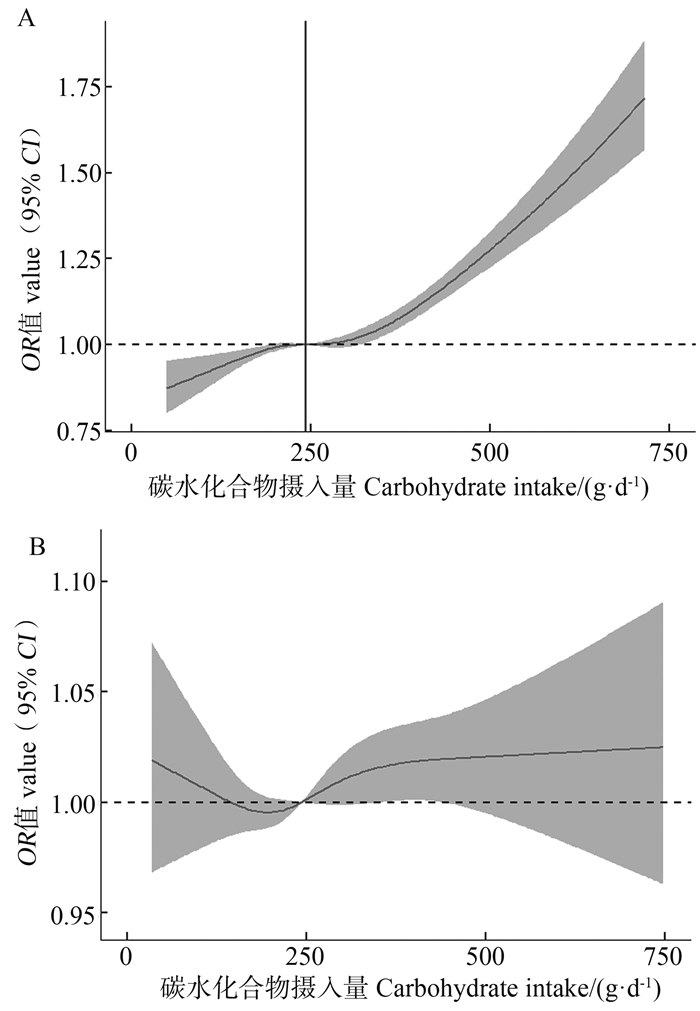
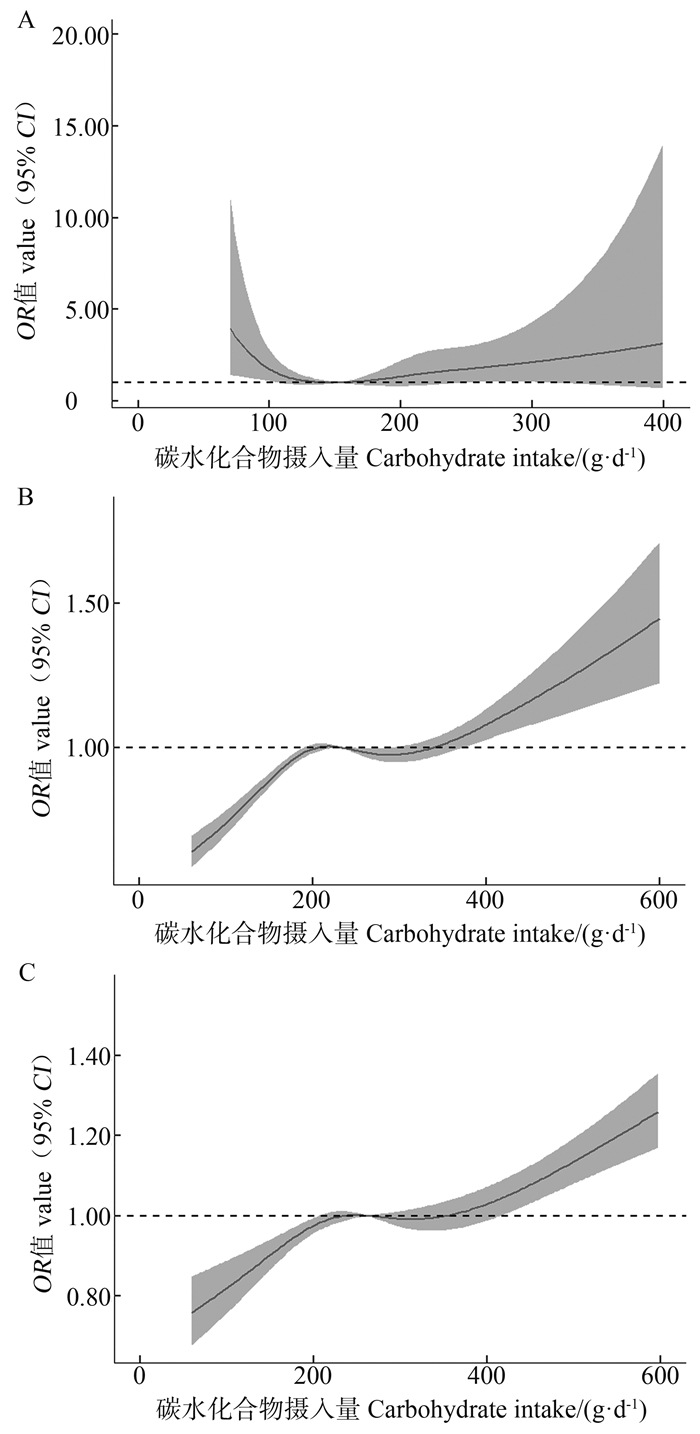
目的 探讨每日碳水化合物摄入量与糖尿病前期患病的关系,为糖尿病前期形成提供证据。 方法 基于美国健康与营养调查2007―2016年数据,纳入与本研究相关且关键指标无缺失的14 299名研究对象。采用非参数协变量均衡广义倾向性评分方法均衡已测得的混杂因素,通过限制性立方样条探究二者关系。 结果 研究人群中位年龄为43岁,糖尿病前期患病率为39.28%。在调整混杂因素后,碳水化合物摄入量与糖尿病前期患病呈非线性关系(P非线性 < 0.001)。与每日摄入量为243.21 g相比,随着碳水化合物摄入量的增加,糖尿病前期的患病风险逐渐升高(OR值逐渐上升)。在高、中和低水平活动人群中,与每日碳水化合物摄入量分别为350.66 g、335.80 g、152.22 g相比,随着碳水化合物摄入量的增加,糖尿病前期的患病风险逐渐升高(OR值逐渐上升)。 结论 碳水化合物摄入量与糖尿病前期患病呈非线性关系,每日摄入超过约240 g的碳水化合物可能是糖尿病前期患病的危险因素。且身体活动水平下降,增加糖尿病前期患病风险的碳水化合物摄入量也会降低。
2025, 29(6): 713-719.
doi: 10.16462/j.cnki.zhjbkz.2025.06.013
摘要:
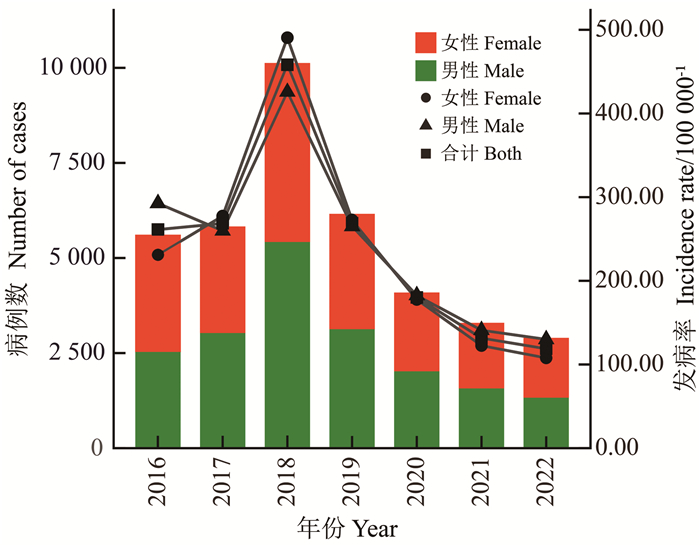
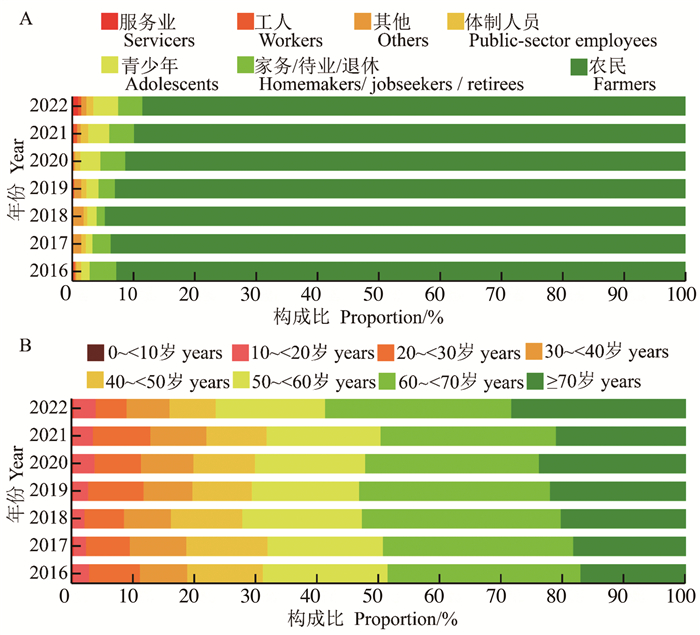
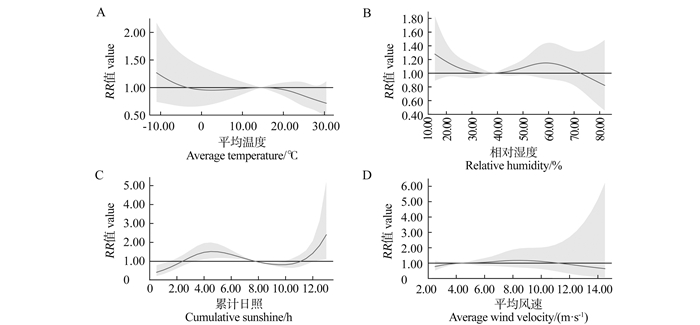
目的 分析和田地区2016―2022年结核病流行特征及探讨气象因素对结核病发病风险的影响,为防控结核病的流行提供参考依据。 方法 用描述性研究分析2016―2022年和田地区结核病在时间、地区和人群中的流行特征,使用分布滞后非线性模型分析不同气象条件对结核病日发病数的影响。 结果 和田地区2016―2022年累计报告结核病38 006例,男性报告病例数高于女性,且农民、60~<70岁患者占比较高; 洛浦县(1 070例)和墨玉县(1 047例)结核病的年均报告病例数较多,且洛浦县结核病年均发病率最高(377.95/10万)。平均温度过低是结核病发病的危险因素,在-11.00 ℃时风险最大,但差异无统计学意义(RR=1.27, 95% CI: 0.74~2.18),且在滞后3 d时,发病风险最高(RR=2.58, 95% CI: 1.44~4.60); 相对湿度较低或较高均会增加结核病的发病风险; 当累计日照时长超过12 h,RR值均>1.00(P<0.05),且在滞后2 d时,结核病发病风险最高(RR=1.10, 95% CI: 0.98~1.24)。 结论 和田地区结核病患者主要集中在农民和高年龄组人群,洛浦县和于田县结核病负担较高,应注意平均温度过低、较低或较高的相对湿度和累计日照时间过长对结核病的影响。
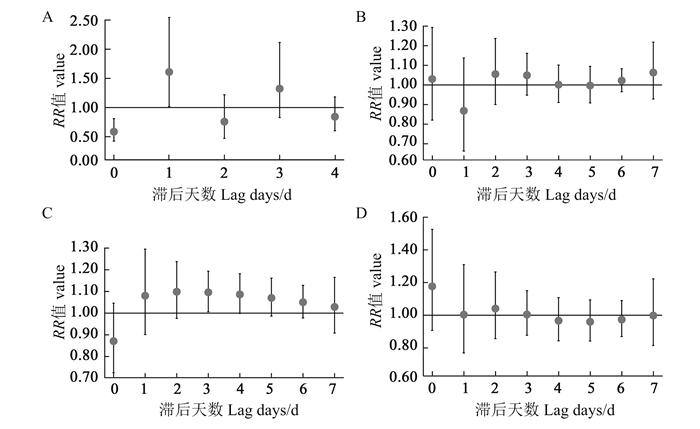
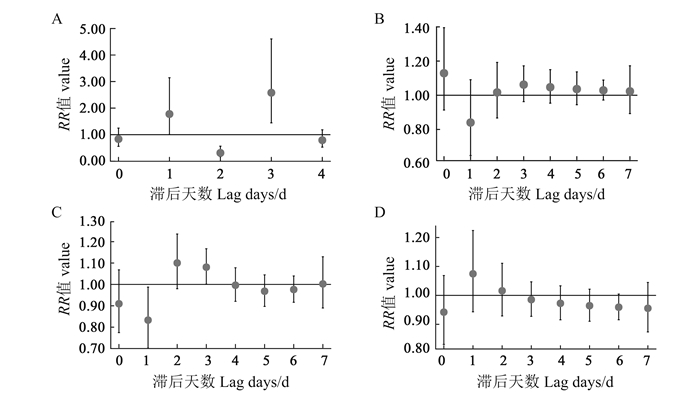
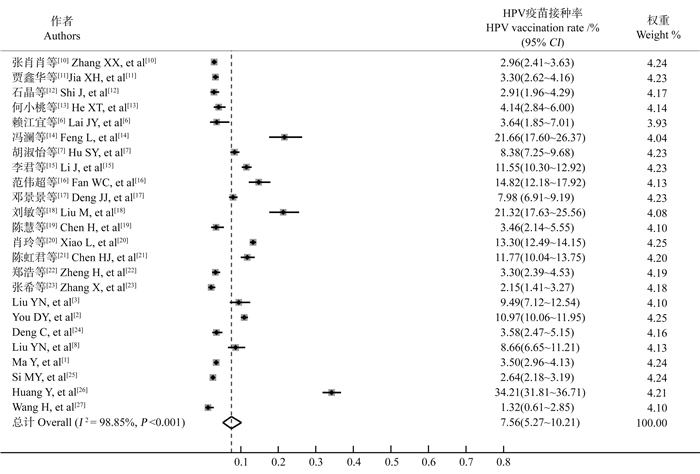
2025, 29(6): 720-726.
doi: 10.16462/j.cnki.zhjbkz.2025.06.014
摘要:
目的 了解中国女大学生人乳头瘤病毒(human papillomavirus, HPV)疫苗接种率及影响因素。 方法 检索2016年以后女大学生HPV疫苗接种相关文献。使用Stata 17.0软件进行Meta分析。 结果 共纳入24项研究,总样本量为40 320人。Meta分析显示,中国女大学生HPV疫苗接种率为7.56%(95% CI:5.27%~10.21%)。影响因素包括城市户籍(OR=2.50, 95% CI:1.79~3.49)、母亲大专及以上学历(OR=1.59, 95% CI:1.13~2.24)、父亲大专及以上学历(OR=1.56, 95% CI:1.16~2.11)、性行为(OR=1.63, 95% CI:1.38~1.92)、知晓HPV疫苗(OR=4.72, 95% CI:3.26~6.28)及对HPV疫苗认知良好(OR=3.96, 95% CI:1.77~8.87)。 结论 中国女大学生HPV疫苗接种率较低,对HPV疫苗的认知是疫苗接种的重要因素。应加强宣传和教育,提高女大学生对HPV疫苗的认知,以推进HPV疫苗的普及和应用。
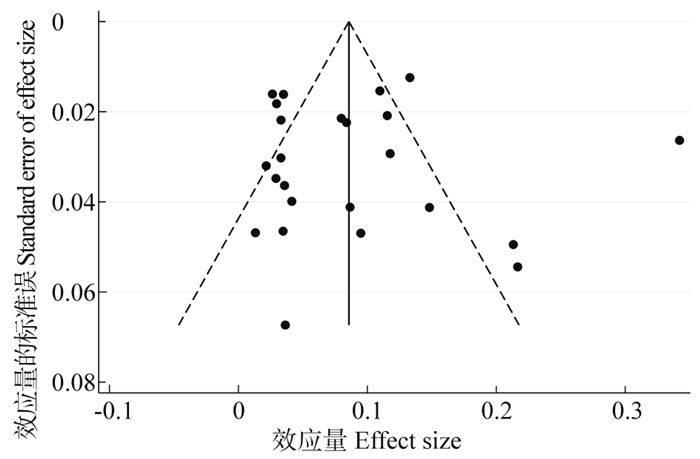
2025, 29(6): 727-730.
doi: 10.16462/j.cnki.zhjbkz.2025.06.015
摘要:
目的 了解福建省≥15岁男性的烟草使用行为、危害认知变化及现在吸烟影响因素,为控烟策略提供依据。 方法 基于2016―2017年和2022年福建省烟草流行调查数据,纳入2 085名和3 062名≥15岁男性为研究对象,数据采用加权后的复杂抽样统计分析方法,通过多因素logistic回归分析现在吸烟率的影响因素。 结果 2022年福建省≥15岁男性现在吸烟率为45.3%,较2016―2017年下降了6.8个百分点; 戒烟率(18.4%)和戒烟意愿(17.5%)仍较低; 烟草危害认知不全面,知晓率虽有上升但仍较低。多因素分析结果显示,25~ < 45岁(OR=1.86, 95% CI: 1.25~2.76)、45~ < 65岁(OR=1.79, 95% CI: 1.20~2.67)男性现在吸烟的风险高于15~ < 25岁; 高中(OR=0.62, 95% CI: 0.48~0.79)、大专及以上(OR=0.31, 95% CI: 0.22~0.43)男性现在吸烟的风险较小学及以下者更低; 知晓吸烟会导致肺癌(OR=0.69, 95% CI: 0.53~0.89)及二手烟会导致成人肺癌(OR=0.70, 95% CI: 0.52~0.95)的男性现在吸烟风险更低。 结论 需加强对25~ < 65岁及低文化程度现在吸烟男性的控烟宣传和戒烟干预,提升烟草危害认知水平,进一步降低现在吸烟率。
2025, 29(6): 731-738.
doi: 10.16462/j.cnki.zhjbkz.2025.06.016
摘要:
目的 探讨中老年人血清维生素与生物衰老速度之间的关联。 方法 基于2017―2018年美国国家健康与营养调查(National Health and Nutrition Examination Survey, NHANES)数据,纳入2 172名>45岁的研究对象。收集包括人口统计学资料、生活习惯和基础疾病史在内的协变量。利用多重线性回归分析模型,评估中老年人血清中的维生素C(vitamin C, VC)、维生素D3(vitamin D3, VD3)、维生素A(vitamin A, VA)和维生素E(vitamin E, VE)与生物衰老速度的关联性。采用分位数g-计算(quantile g-computation, QGCOMP)、加权分位数和(weighted quantile sum, WQS)2种回归方法,分析不同血清维生素对生物衰老速度的影响及其联合效应。 结果 研究对象平均年龄为(62.69±10.29)岁,男性与女性间血清维生素水平的差异均有统计学意义:VD3(Z=-2.376, P=0.017)、VC(Z=-7.230, P < 0.001)、VA(Z=6.418, P < 0.001)、VE(Z=-7.324, P < 0.001)。多重线性回归分析表明,VC与生物衰老速度呈负相关(β=-0.032, 95% CI: -0.041~-0.023, P < 0.001)。WQS与QGCOMP分析显示,血清维生素联合作用减缓衰老速度(β=-0.459, 95% CI: -0.585~-0.333, P < 0.001; β=-0.381, 95% CI: -0.538~-0.223, P < 0.001),VC在延缓衰老中起主要作用(权重:0.936, 0.885)。 结论 血清维生素是生物衰老的保护性因素,VC在减缓衰老速度的联合效应中作用最显著。
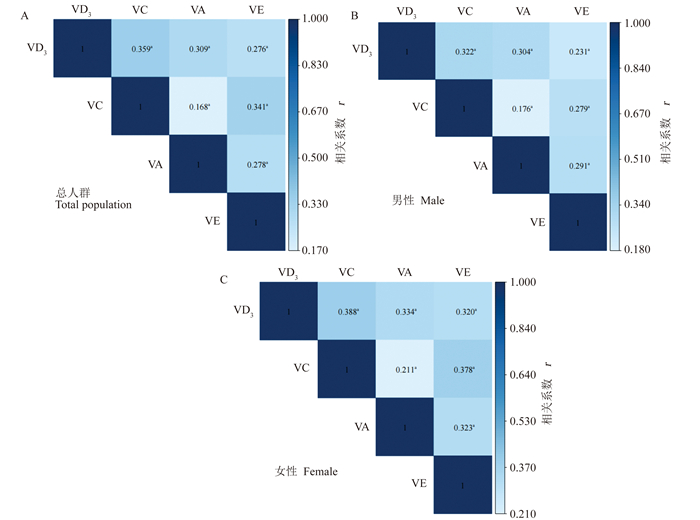
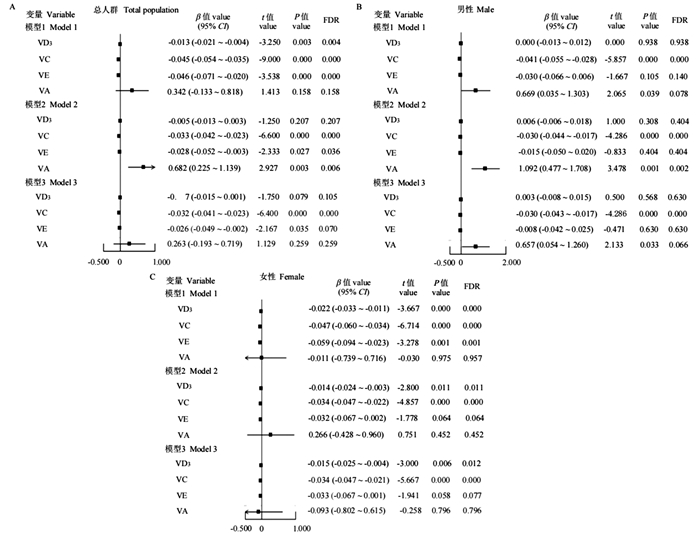
2025, 29(6): 739-744.
doi: 10.16462/j.cnki.zhjbkz.2025.06.017
摘要:
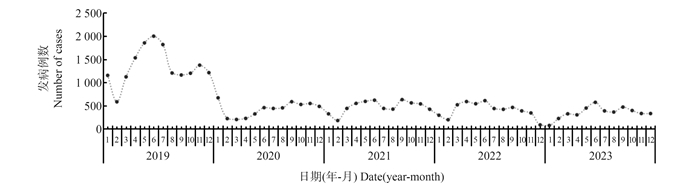
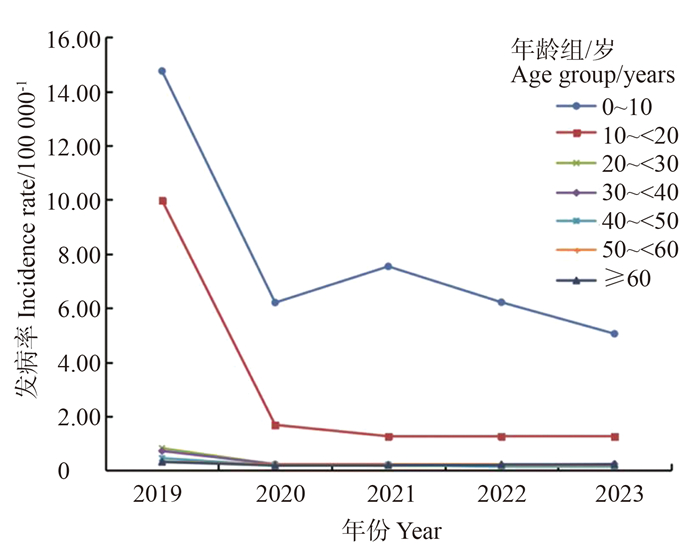
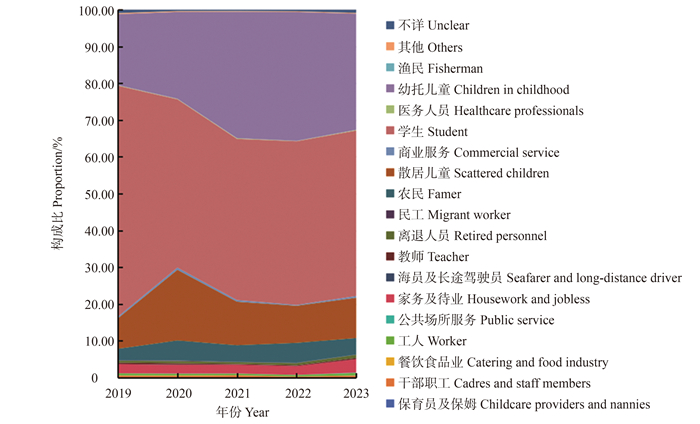
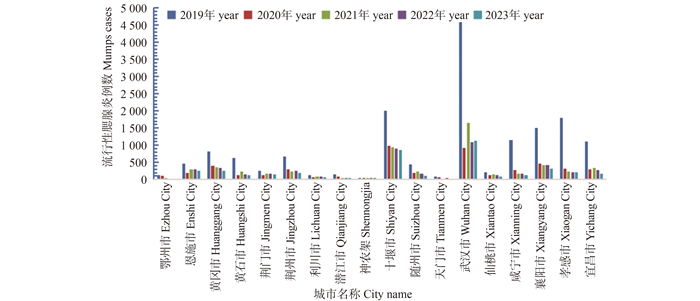
目的 分析2019―2023年湖北省流行性腮腺炎(简称流腮)的流行病学特征,为流腮防控提供科学依据。 方法 基于2019―2023年中国疾病预防控制信息系统中湖北省流腮患者的流行病学史、临床诊断个案数据,年龄范围为全人群,整理报告卡信息包括性别、年龄、时间分布、人群分布和地区分布等。采用χ2检验或Fisher确切概率法分析其流行病学特征。 结果 2019―2023年湖北省共报告流腮36 154例,年均报告发病率为12.33/10万。2019年流腮年均报告发病率(27.35/10万)和发病构成比(44.84%)最高,2020―2023年逐步降低。时间分布上,流腮发病主要集中在春季、夏季和秋季,不同月份发病比率差异均有统计学意义(均P<0.001)。性别分布上,男性流腮发病比率(59.43%)高于女性(40.57%),差异均有统计学意义(均P<0.001)。年龄分布上,2019―2023年流腮高发年龄为0~<20岁,≥60岁老年人不易发病,不同年龄发病率差异均有统计学意义(均P<0.001)。人群分布上,学生(52.86%)和幼托儿童(25.91%)的流腮发病比率较其他人群高,差异均有统计学意义(均P<0.001)。湖北省不同城市流腮发病比率差异有统计学意义(P<0.001)。 结论 2019―2023年湖北省人群流腮发病率总体上呈下降趋势,春季、夏季和秋季高发,高发年龄为0~<20岁,应重点关注儿童,加强对学校和幼托机构的防控力度。

| 主 管: | 国家疾病预防控制局 |
| 主 办: | 中华预防医学会 安徽医科大学 |
| 主 编: | 叶冬青 |
| 出 版: | 中华疾病控制杂志编辑部 |
| 通讯地址: | 安徽省合肥市梅山路81号安徽医科大学 |
| 电 话: | 0551-65161171 |
| 邮 箱: | zhjbkz@vip.163.com |





